Cansino
> Cansineando a los políticos
March 16, 2020
A veces los políticos y las políticas de turno hablan mucho sobre lo que ellos dicen que es importante para la ciudadanía, y a su vez, muchas otras veces encontramos que no hacen lo que dicen.
Por ello, se me ha ocurrido el acceder a las agendas públicas de ciertos políticos, en particular presidentes de comunidades autónomas, hacer un scrapping de las mismas puesto que no ofrecen un API público para consultarlas, y almacenar los eventos de cada día en un repositorio. De esta manera, seríamos capaces de consultar los citados eventos de una manera estructurada utilizando técnicas de BigData, y verificar si lo que estos políticos hacen (porque está en sus agendas) se alinea con lo que realmente prometen.
Es cierto que este enfoque tendría cierto sesgo al no publicar éstos realmente lo que hacen, sino que se centran únicamente en compartir un mero texto muy vago, con poca literatura: ‘Asiste al consejo blah blah blah’, supongo que para que no pillarse los dedos. Pero es lo que tenemos. ¡Ya nos gustaría que los gobernantes fueran más transparentes y nos facilitaran más información!
Con todo esto en la mano, queremos procesar esos eventos de las agendas, quitar las palabras de paso en castellano (preposiciones, conjunciones, etc.), y almacenar cada evento en un repositorio que permita realizar analíticas sobre este conjunto de datos. Y aprovechando que Elasticsearch es un almacenamiento orientado a búsquedas, y que trabajo en Elastic, qué mejor que aprovechar su potencia para almacenar en él las agendas, procesar el contenido, y mostrar gráficos de interés en Kibana, como por ejemplo una nube de tags con las palabras más utilizadas. El resultado para Castilla-La Mancha, podría ser algo así:
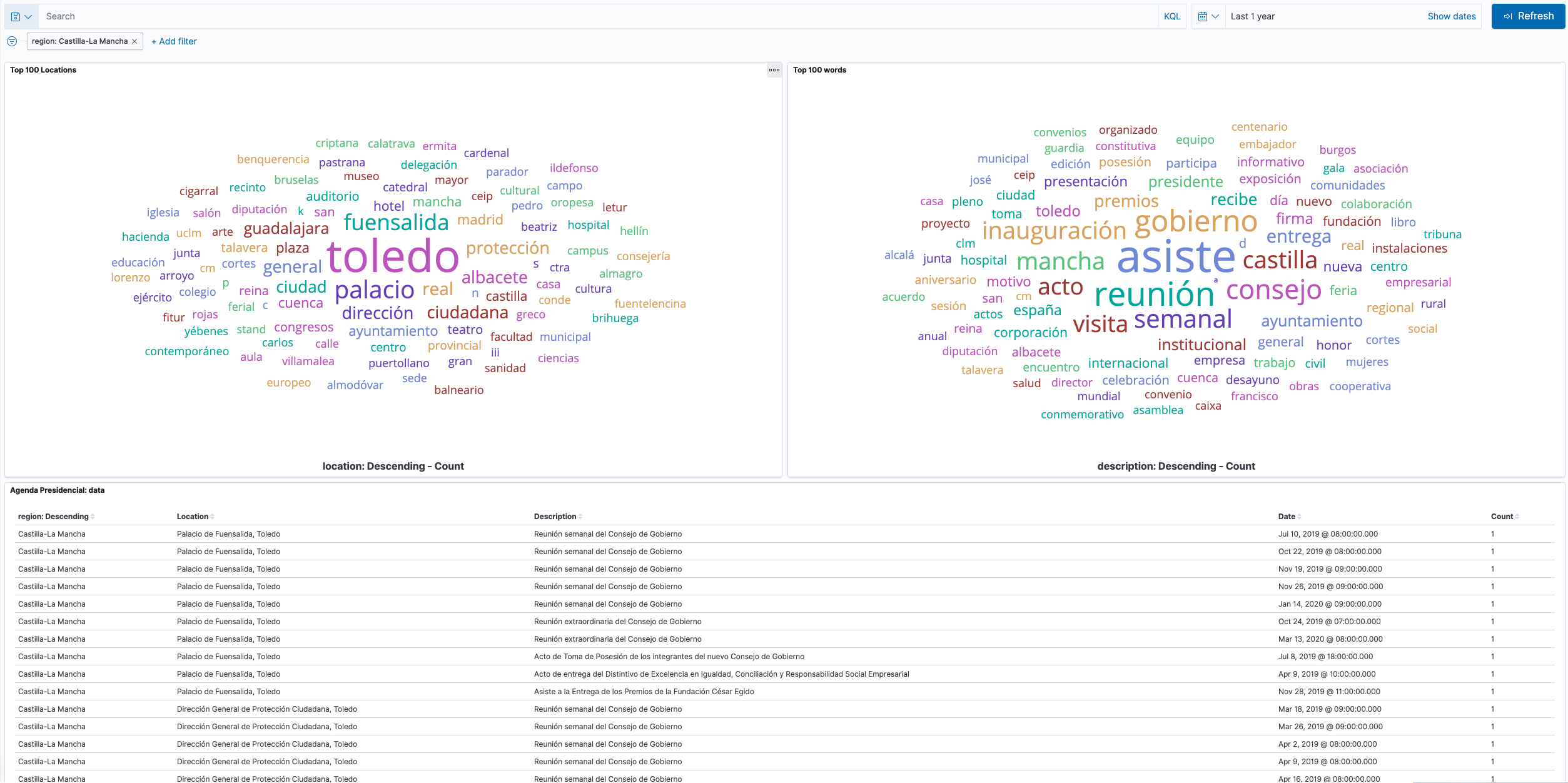
Como podéis comprobar, muchos políticos simplemente “asisten” a reuniones. Como ya dije antes, como ciudadano me encantaría que fueran mucho más transparentes de lo que en realidad son.
Es por ello que he llamado a este servicio Cansino, porque persigue de manera incansable al político de turno, como el famoso Cansino Histórico de José Mota.
Stack tecnológico
En cuanto al stack, os he dado unas pinceladas del almacenamiento primario, Elasticsearch, así como la aplicación de visualización de datos, Kibana. Hablaré de ellos más adelante. Pero, ¿cómo cogemos, procesamos y enviamos las agendas al almacenamiento principal?
Aquí es donde aparece la palabra scrap, que no es otra cosa que coger el HTML completo de la página web donde se muestra un dato, y extraer del mismo la información necesaria seleccionando los elementos y tags HTML de interés. Por tanto supone un análisis previo de la estructura de la página, para identificar cómo se presenta la información de interés.
Es importante hacer una parada aquí para pedir encarecidamente que uséis atributos ID de manera consistente: un único ID por página, y que utilicéis un marcado HTML que no sea una auténtica lasaña de elementos anidados sin semántica alguna. Dicho ésto, vamos al programa que hace el scrapping.
Cansino es un programa escrito en Go que procesa documentos HTML, siendo este documento el correspondiente a la agenda para un día concreto del político de interés. Para ello, coge cada evento de la agenda de ese día, extrae la información de interés y la envía al almacenamiento. Esta información de interés se corresponde con los siguientes campos:
- id: representando un identificador único del evento.
- date: con la fecha y hora del evento.
- description: con las palabras clave de la descripción del evento.
- originalDescription: con la descripción original completa.
- location: con las palabras clave de la localización del evento.
- locationDescription: con la localización original completa.
- attendance: que es a su vez una estructura, una por persona asistente al evento, con los campos:
- job: con el puesto de la persona.
- fullName: con el nombre completo.
- owner: con el cargo de la persona dueña de la agenda.
- region: con el nombre de la región.
El scrapping es posible gracias a Go-Colly, que facilita muchísimo esta tarea. Sin embargo, en algún caso he necesitado utilizar htmlquery para parsear directamente el HTML retornado por peticiones Ajax.
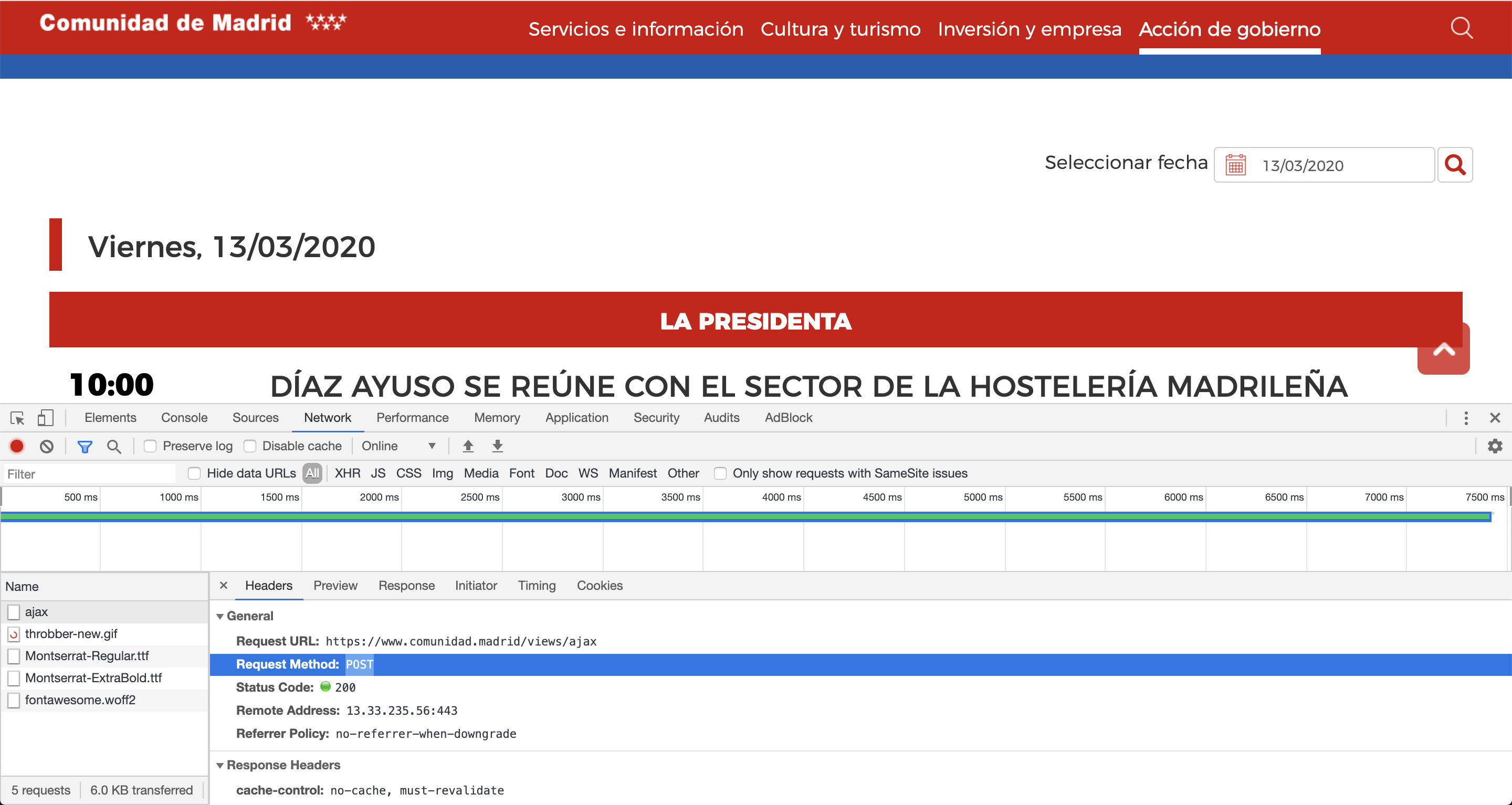
En relación a ésto último, es muy frustrante ver cómo la web de la Comunidad de Madrid se folla los verbos HTTP y utiliza POST para retornar los eventos de un día en particular 🤦♀️.
Una vez capturada la información de interés, y modelada en una estructura de datos, la quiero indexar en Elasticsearch, por tanto hay que definir los tipos de datos de una manera consecuente a las operaciones que quiero realizar, que no es otra que hacer una búsqueda de tipo full-text en la descripción y en la localización de los eventos, para saber de qué hablan nuestros políticos y, también importante, desde dónde lo hacen. Por tanto, los tipos para cada campo son:
- id: keyword.
- date: date.
- description: text.
- originalDescription: keyword.
- location: text.
- locationDescription: keyword.
- attendance:
- job: text.
- fullName: text.
- owner: keyword.
- region: keyword.
Simplemente añadiendo el cliente oficial de Go de Elasticsearch a la aplicación es suficiente para indexar el dato, pero primero, nada más capturar un evento de la web, lo analizo con un Analyzer, que es el responsable de quitar en la descripción y la localización las palabras de paso en castellano (adverbios, pronombres, preposiciones, conjunciones, etc.). Esta funcionalidad ya la trae de serie Elasticsearch, por tanto sólo hay que definirlo en la definición del índice.
"settings": {
"analysis": {
"analyzer": {
"spanish_stop": {
"type": "stop",
"stopwords": "_spanish_"
}
}
}
},
La carga inicial de todos los documentos, esto es, desde el primer día en el que tienen datos las agendas, la hice en mi equipo, pero he añadido una GitHub Action que se ejecuta cada día a ciertas horas, a modo de cron, para almacenar los eventos del día actual.
Hay que reconocer que Extremadura tiene datos desde el 2011! Castilla-La Mancha conserva un histórico desde el 2017, y la Comunidad de Madrid desde el 2019.
Una cosa que he implementado para entender qué está pasando en Cansino mientras se ejecuta, consiste en instrumentar el código con el Agente de APM para Go de Elastic, creando trazas de la aplicación cada vez que se almacena un evento. De esta manera puedo saber los tiempos de ejecución y el estado del runtime de Go, entre otras cosas.
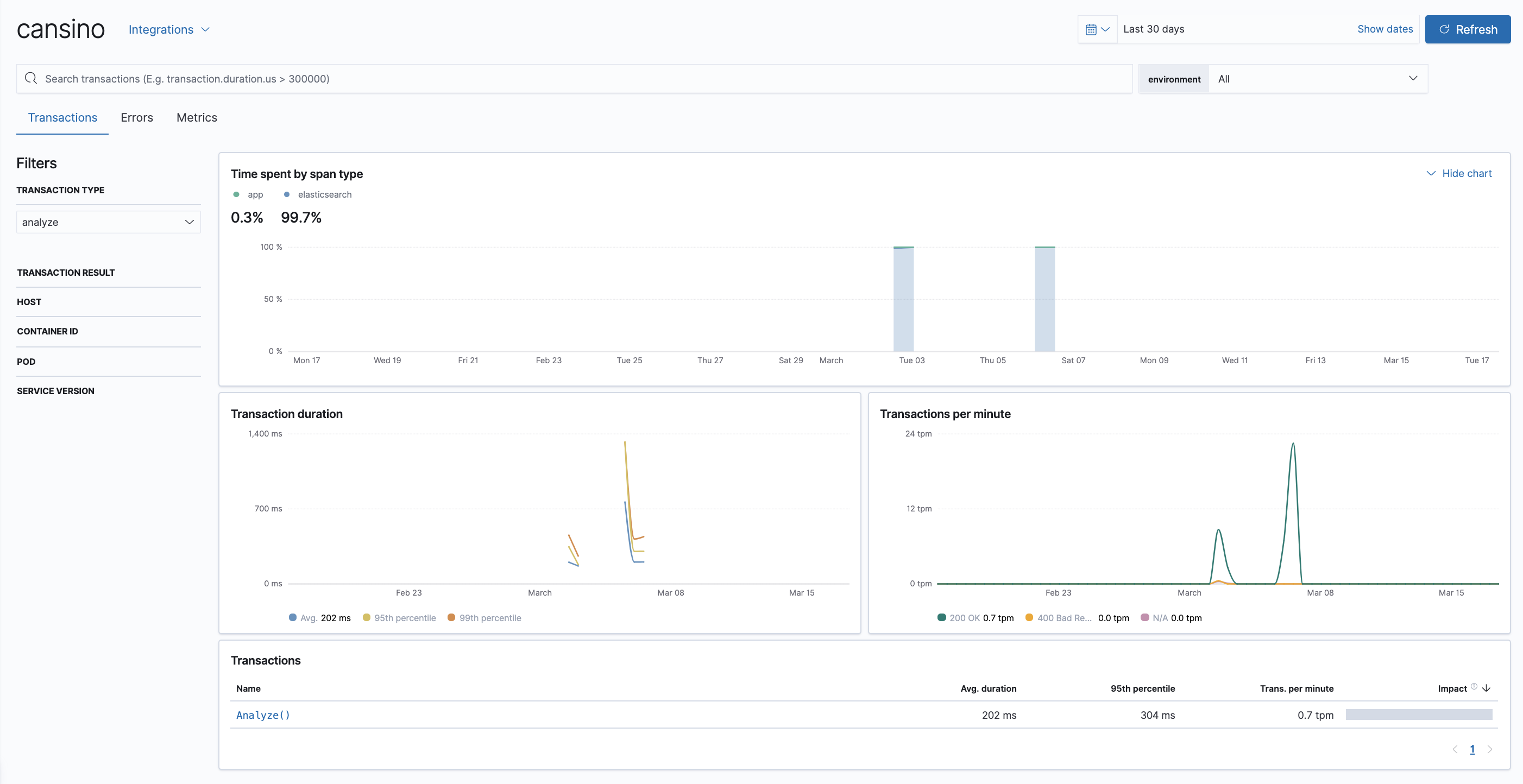
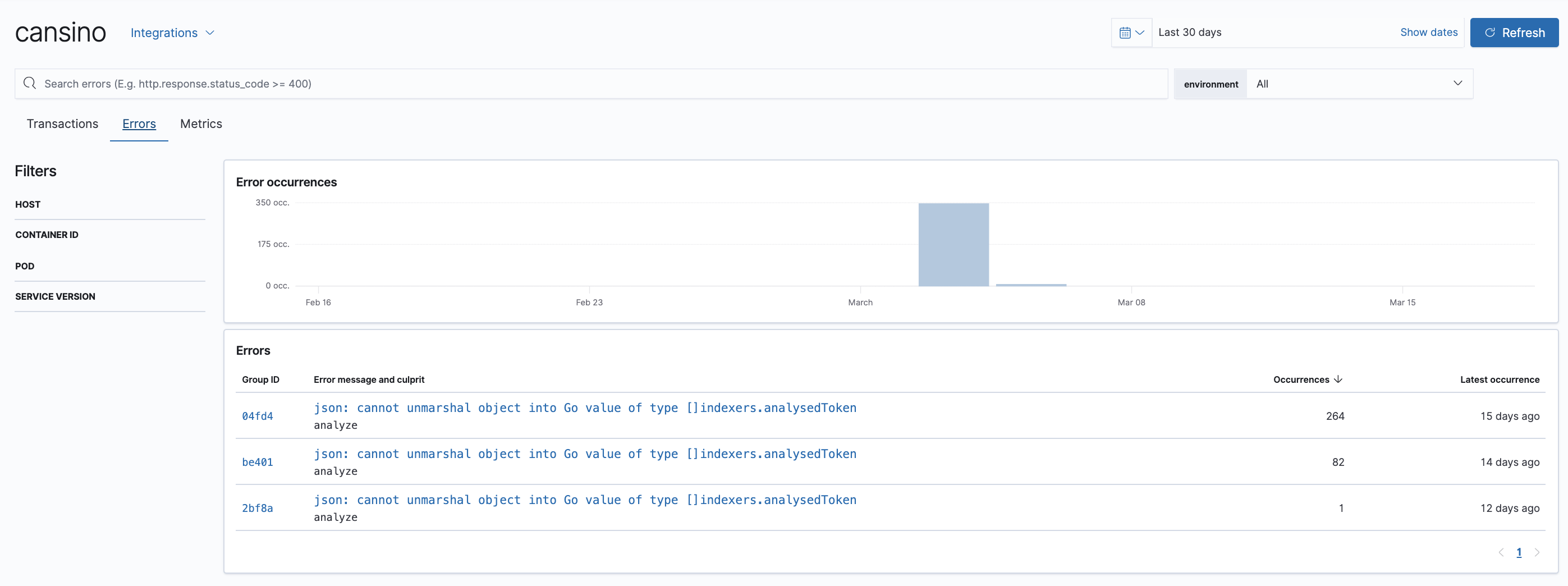
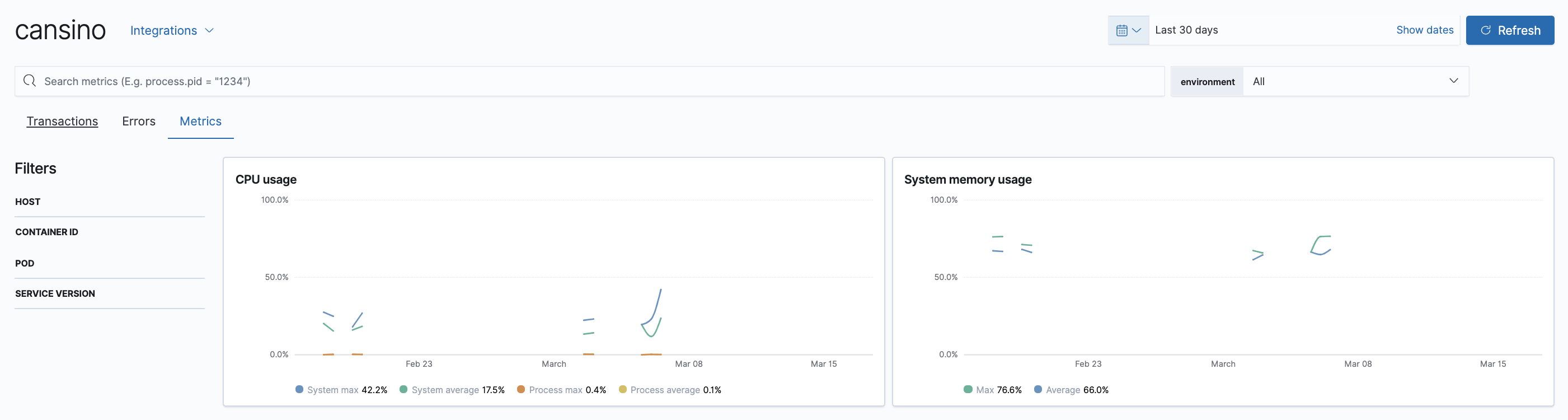
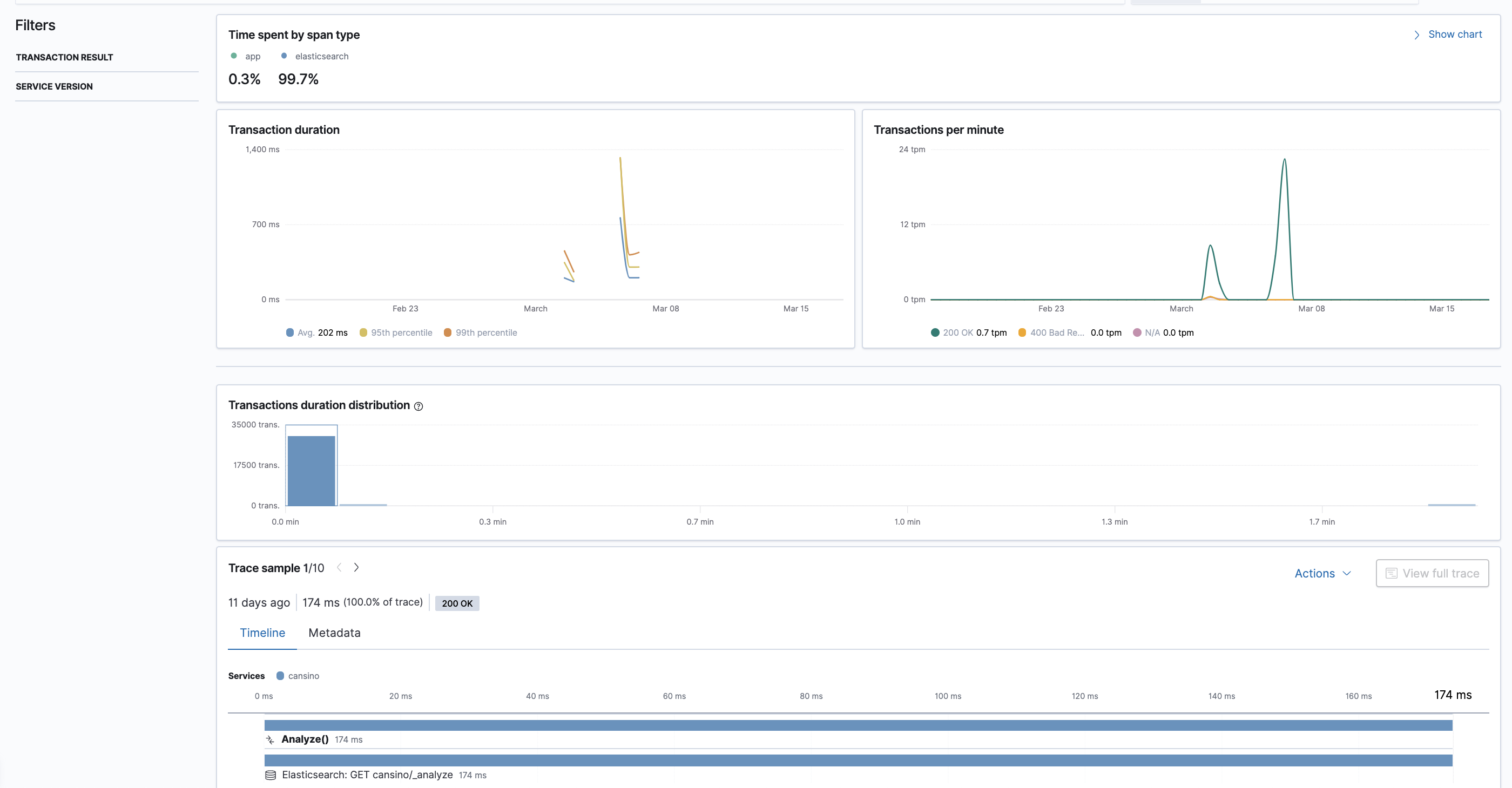
Configurando el entorno para que las siguientes variables estén disponibles es más que suficiente para decirle al agente dónde tiene que enviar las trazas, métricas y errores:
ELASTIC_APM_SECRET_TOKEN=<APM Token>
ELASTIC_APM_SERVER_URL=<URL del APM Server>
ELASTIC_APM_SERVICE_NAME=cansino
ELASTIC_APM_SERVICE_VERSION=1.0.0
ELASTIC_APM_CAPTURE_BODY=all
Para controlar el flujo de ejecución del programa, Cansino es una CLI escrita utilizando Cobra, con dos únicos comandos:
- chase, que procesa todos los eventos desde los inicios de cada agenda.
-
**get [-d –date 2020-04-14]**, el cual procesa los eventos de un único día, pasado por parámetro en formato YYYY-MM-dd. Si el valor de este parámetro es igual a la cadena “Today”, entonces se usará la fecha del sistema, cargando los eventos de hoy. Este comando es el utilizado por la GitHub Action para capturar los eventos del día.
Despliegue y operaciones
Le doy un apartado especial a esto porque considero muy importante el operar un servicio. Si tenemos los conocimientos adecuados para asegurar la estabilidad del entorno, me parece bien que lo operemos nosotros mismos, pero y si falla el disco, o la memoria, o el servidor no responde a más peticiones… SaaS to the rescue!
Podríamos tener un Elastic Stack desplegado en la misma red que el Cansino para enviar los datos ahí, pero no tendría mucho valor el tenerlos en local. Mi idea es poder compartir esta información en algún momento, así que por ello, qué mejor opción que utilizar el Cloud de Elastic para alojar los datos, y que sean ellos los que lo operen por mí, con un modelo de pago por uso (ojo que tiene un trial de 15 días, ¡aprovechadlo!). Es cierto que al ser empleado de Elastic tengo un cluster chiquitito para mí, y por eso he metido a Cansino aquí, pero también es verdad que utilizar Elastic Cloud en el arranque de un proyecto te puede ahorrar muchísimo tiempo de setup y operaciones, para luego más adelante ya decidir si quieres hacerlo in-house o continuar con el modelo cloud. En este clúster tengo un Elasticsearch, un Kibana, y un APM Server (o middleware que recibe las trazas del agente de APM para Go, y se las envía al Elasticsearch en un formato conocido), por lo que con un par de click Cansino ya podría empezar a funcionar y enviar datos para ser procesados.
Para enviar los datos al Cloud hay que configurar el cliente de Elasticsearch de la siguiente manera:
cfg := es.Config{
// configuración de Elastic Cloud
CloudID: os.Getenv("ELASTIC_CLOUD_ID"),
Password: os.Getenv("ELASTIC_CLOUD_AUTH"),
Username: os.Getenv("ELASTIC_CLOUD_USERNAME"),
// configuración para el agente de APM para Go
Transport: apmes.WrapRoundTripper(http.DefaultTransport),
}
client, err := es.NewClient(cfg)
Y no hay nada más que hacer ahí 😊.
En cuanto a la parte de visualización, he creado varias visualizaciones específicas en Kibana en función de lo que quería obtener, como por ejemplo:
- comparar números de eventos en torno a ciertas fechas de interés, como elecciones…
- nube de tags con las palabras más utilizadas en las descripciones de los eventos de la agenda
- nube de tags con las palabras más utilizadas en las localizaciones de los eventos de la agenda
¡Pero estoy seguro que se te ocurren muchos más!
¿Y qué regiones estoy analizando?
Cansino analiza, por el momento, tres regiones de España:
- Castilla-La Mancha (mi región!)
- Extremadura
- Madrid
¿Qué más se podría hacer con el Stack?
Podríamos además aumentar los logs de Cansino y enviarlos con Filebeat al Stack, de modo que pudiésemos correlar eventos de log con trazas y/o métricas de la aplicación.
No soy para nada un experto en ML, pero seguro que podríamos aplicar Machine Learning y aprender un poco de los eventos, su frecuencia y su temática, y observar anomalías.
¿Se os ocurre algo más?
¿Y si quiero analizar qué dicen en mi región?
Si quieres que añada otra región, please abre una issue.
¿Quieres acceder a los dashboards?
Si quieres acceder a un dashboard, please envíame un email a mdelapenya at gmail.com.